















Ah, you would like some more information on Validiffer's use case? No problem! Let's see if you can relate to the following:
Are you tired of trying to onboard large sets of data which should be correctly formatted but instead arrives with changed headers, missing columns, alternated spacing, disappeared values, different formatting, and more?
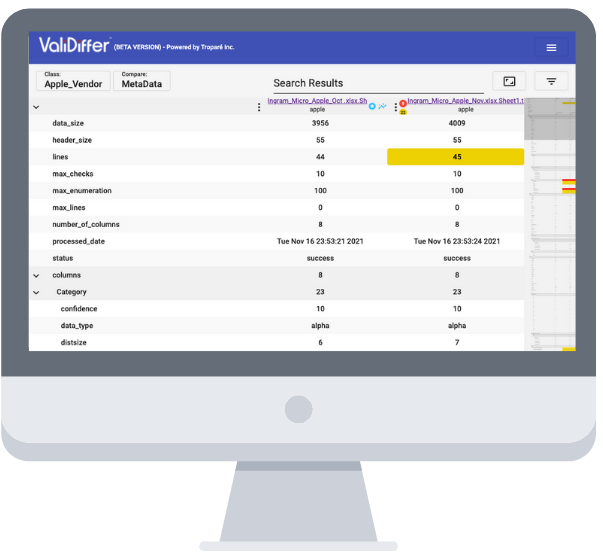
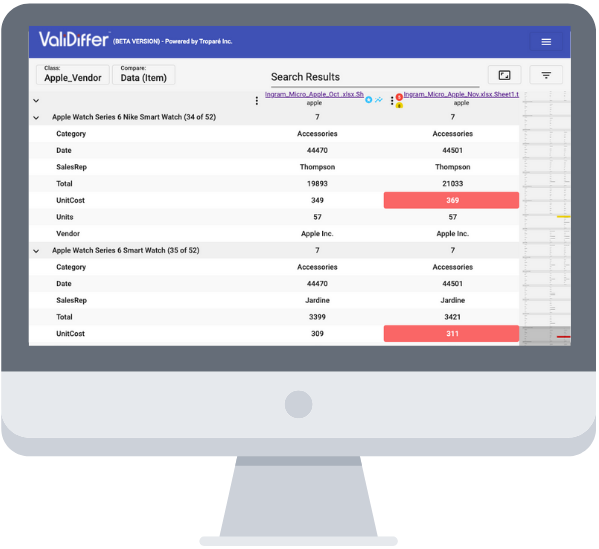
All too often, data files get onboarded (or should we say: ‘shoved over’) with incorrectly formatted data, which requires both you and the sending party to either revert the process, demand a new file, re-upload or download a secondary file, or manually re-edit the file – all costing a significant amount of time and money. ValiDiffer's core competence is providing metadata trending analytics prior to import (in what we call 'data escrow'), to validate your (scheduled) data dumps and workflow(s). ValiDiffer utilizes AI, neural networks, and machine learning as an aid to automatically validate, map, fix, and transform as much of your data into your ideal onboarding state as possible.
ValiDiffer's visual summarized analyses are instantly reported back to the uploading party, pointing out precise problems or concerns with the file (e.g. invalid headers, missing fields, malformed zip codes, required columns are empty or missing values, etc.) prior to the receiving party ingesting the data. By notifying the uploading party of defective files and identifying issues prior to entering transfer and load phases, both uploading and receiving parties can be assured of more consistently correct data onboarding sequences, virtually eliminating the costly 'redo' cycle.
This tool is unique in the industry and through its twelve (12) month ALFA phase has garnered savings upwards of $100,000+ in technical support costs for a single client doing bi-weekly file imports.
Spend less time onboarding data, and more time using it.